Herewith, a rant: multiple transport bindings considered harmful.
I still hear this and it's getting increasingly annoying. People consider it a good thing for a standard to be able to run over HTTP, BEEP and something else. Has this ever proven to be a good idea? Layering is good for other reasons, but not because it gives implementors a choice that leads to interoperability failure in many cases.
Is it a failure on the part of the designer to understand the usage characteristics of their protocol, and successfully map that onto TCP (connection-oriented), HTTP (stateless respond-and-forget) or something else?
SOAP is supposed to be transport-independent and offer choice, but as I overheard last week, there's a reason they call it web services. And the ultimate in multiple-transport wankery: I once heard somebody propose a schema which they said would run over SOAP or HTTP.
Are there use cases I'm unaware of, where this has been a really good thing for some standard?
Wednesday, November 12, 2008
I'd like to be able to explain the important confluence of several ad-hoc Web standards to various people, so I paid attention Monday at IIW. This is the diagram I saw:
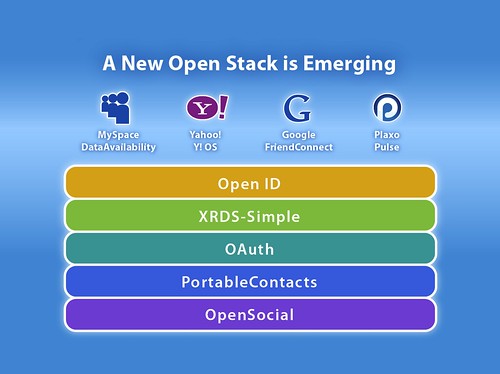
I can't call this a stack. I just can't. It's not a protocol stack or an API stack or a library stack. The best I can say is that "Some people call it a stack". There's no layering relationship between these things; there's not even a sequence or an order.
PortableContacts extends Open Social and the rest are independent proposals that work well together. It's a suite, a cluster or a collection of protocols/APIs. Here's a first stab at a moderately simple diagram that does not mislead:

Comments?
I can't call this a stack. I just can't. It's not a protocol stack or an API stack or a library stack. The best I can say is that "Some people call it a stack". There's no layering relationship between these things; there's not even a sequence or an order.
PortableContacts extends Open Social and the rest are independent proposals that work well together. It's a suite, a cluster or a collection of protocols/APIs. Here's a first stab at a moderately simple diagram that does not mislead:

Comments?
Sunday, November 09, 2008
The idea of using native HTTP resources to RESTfully access an email store is not only an old idea, it's been implemented many times. Some Web mail architectures are even somewhat RESTful although the purest implementations are not themselves Web UIs -- these RESTful email interfaces have typically been built to support Web UI frontends in a classic tiered architecture.
I have been talking about this for so long that it seems self-explanatory. Emails can be HTTP resources with persistent URLs and machine-readable representations. Mailboxes can also be HTTP resources with persistent URLs and machine-readable listings of contents, we just have to agree how to represent those listings. Here's my proposal.
Atom feeds is my choice for organizing those listings. I think it's worth explaining the two overriding reasons why.
I have been talking about this for so long that it seems self-explanatory. Emails can be HTTP resources with persistent URLs and machine-readable representations. Mailboxes can also be HTTP resources with persistent URLs and machine-readable listings of contents, we just have to agree how to represent those listings. Here's my proposal.
Atom feeds is my choice for organizing those listings. I think it's worth explaining the two overriding reasons why.
- Atom allows clients to just GET a representation of a feed, and the feed can contain an arbitrarily long list of items, but paged according to the server's needs. This is a great allocation of responsibility, making client logic simple and putting server performance in the server's hands.
- The default model for feeds is that the same object can be in more than one feed. This is very important for the usability of email going forward. I know a few people who organize their mail into strict hierarchical collections, typically using IMAP, and find old email by jumping to the right place in the hierarchy -- but I know far more who rely on giant inboxes, saved searches, flagged email or tagging. The default model for feeds directly accomodates all those usage models.
Subscribe to:
Posts (Atom)
